start_kernel part V
trim RAM not covered by MTRRs
Some buggy BIOSes don't setup the MTRRs properly for systems with certain memory configurations. This routine checks that the highest MTRR matches the end of memory, to make sure the MTRRs having a write back type cover all of the memory the kernel is intending to use. If not, it'll trim any memory off the end by adjusting end_pfn, removing it from the kernel's allocation pools, warning the user with an obnoxious message.
mtrr_trim_uncached_memory (end_pfn=32766)
at arch/x86/kernel/cpu/mtrr/cleanup.c:993
993 {
(gdb) n
1004 if (!is_cpu(INTEL) || disable_mtrr_trim)
(gdb) p disable_mtrr_trim
$18 = 0
(gdb) n
1035 return 0;
determine low and high memory ranges
All of RAM fits into lowmem - but if user wants highmem artificially via the highmem=x boot parameter then create it
find_low_pfn_range () at arch/x86/mm/init_32.c:699
699 if (max_pfn <= MAXMEM_PFN)
(gdb) p /x max_pfn
$19 = 0x7ffe
(gdb) n
696 {
(gdb)
699 if (max_pfn <= MAXMEM_PFN)
(gdb)
700 lowmem_pfn_init();
(gdb) s
lowmem_pfn_init () at arch/x86/mm/init_32.c:625
625 max_low_pfn = max_pfn;
(gdb) p max_pfn
$20 = 32766
(gdb) n
627 if (highmem_pages == -1)
(gdb) p highmem_pages
$21 = 4294967295
(gdb) p /x highmem_pages
$22 = 0xffffffff
(gdb) n
625 max_low_pfn = max_pfn;
(gdb)
627 if (highmem_pages == -1)
(gdb)
628 highmem_pages = 0;
(gdb)
630 if (highmem_pages >= max_pfn) {
(gdb)
635 if (highmem_pages) {
(gdb)
647 }
(gdb)
find_low_pfn_range () at arch/x86/mm/init_32.c:703
703 }
setup bios corruption check
Find memory aread need to be scanned and update the found address and its size to a dedicated array.
early reserve memory for brk erea
Reserve memory for brk area.
About brk here are some information from the description of heap
The heap area commonly begins at the end of the .bss and .data segments and grows to larger addresses from there. The heap area is managed by malloc, calloc, realloc, and free, which may use the brk and sbrk system calls to adjust its size (note that the use of brk/sbrk and a single "heap area" is not required to fulfill the contract of malloc/calloc/realloc/free; they may also be implemented using mmap/munmap to reserve/unreserve potentially non-contiguous regions of virtual memory into the process' virtual address space). The heap area is shared by all threads, shared libraries, and dynamically loaded modules in a process.
initialize memory map
Setup the direct mapping of the physical memory at PAGE_OFFSET. This runs before bootmem is initialized and gets pages directly from the physical memory. To access them they are temporarily mapped.
set NX-bit if nx enabled, active pse and pge in cpu mask if dedicated feature available, finally initialize page table.
(gdb) p /x max_pfn_mapped
$45 = 0x7ffe
reserve memory for initrd
initrd (initial ramdisk) is a scheme for loading a temporary root file system into memory, which may be used as part of the Linux startup process. initrd and initramfs refer to two different methods of achieving this. Both are commonly used to make preparations before the real root file system can be mounted.
ramdisk_image = 0x77b5000
ramdisk_size = 0x290498
ramdisk_end = 0x7a45498
end_of_lowmem = 0x7ffe000
initrd finnaly locates at low memory
initrd_start = 0xc77b5000
initrd_end = 0xc7a45498
override I/O delay port
void __init io_delay_init(void)
{
if (!io_delay_override)
dmi_check_system(io_delay_0xed_port_dmi_table);
}
Inside io_delay_init it first check the value of io_delay_override which is set when early parameter io_delay exists in linux start command line. If the option of io_delay doesn't set in command line, do further actions with dmi_check_system with io_delay_0xed_port_dmi_table as input parameter. io_delay_0xed_port_dmi_table is a list of quirk table for systems that misbehave (lock up, etc.) if port 0x80 is used. Scan the list with current system parameters, if matches call the configured function of the list item.
io_delay= [X86] I/O delay method
0x80
Standard port 0x80 based delay
0xed
Alternate port 0xed based delay (needed on some systems)
udelay
Simple two microseconds delay
none
No delay
parse the ACPI tables
The ACPI is the now preferred (and bloated) way of gathering information about the system.
The bread of ACPI to most OS purposes involve reading through the complicated mess of tables.
The first table is one that has to be searched for much like the MP tables (Exception being if you are using EFI). It is the RSDP table. This table contains the information necessary to find the other gazillion tables in existence.
The table's actual definition will be listed below.
1 Tables
1.1 RSDP
1.2 RSDT
1.3 XSDT
1.4 MADT
1.4.1 LocalAPIC Entry
1.4.2 IO APIC Entry
1.4.3 Interrupt Source Override
Inside acpi_boot_table_init it first initialize the ACPI boot-time table parse with acpi_table_init which locate and checksum all ACPI tables. Next try to find table with id BOOT, if success execute handler, the handler is a function pointer for further actions. Finally ACPI maintains a blacklist based on the table headers. But this blacklist is somewhat primitive.
When an entry matches the system, it either prints warnings or invokes acpi=off.
Inside early_acpi_boot_init process the Multiple APIC Description Table (MADT), if present.
setup node map and Boot Memory Allocator
About Boot Memory Allocator please reference chapter 5 of Understanding Linux Virtual Memory Manager
Here are value of low and high pfn before allocate memory region for high memory.
(gdb) printf "max_pfn = 0x%x\n", max_pfn
max_pfn = 0x7ffe
(gdb) printf "max_low_pfn = 0x%x\n", max_low_pfn
max_low_pfn = 0x7ffe
Before setup boot memory allocator, the result is
(gdb) printf "num_physpages = 0x%x\nhigh_memory = 0x%x\nmax_mapnr = 0x%x\n", num_physpages, high_memory, max_mapnr
num_physpages = 0x7ffe
high_memory = 0xc7ffe000
max_mapnr = 0x7ffe
Next we will focus on setup_bootmem_allocator, calculate bitmap side in pages for low memory with bootmem_bootmap_pages, find a free area for the bitmap with find_e820_area, size of bitmap is 4096.
(gdb) printf "bootmap = 0x%x\nbootmap_size = 0x%x\n", bootmap, bootmap_size
bootmap = 0x35000
bootmap_size = 0x1000
Reserve memory range for the bitmap with reserve_early, it first have drop_overlaps_that_are_ok() drop any pre-existing 'overlap_ok' ranges, so that we can then reserve this memory range without risk of panic'ing on an overlapping overlap_ok early reservation, after that involve __reserve_early for memory allocation.
(gdb) n
784 reserve_early(bootmap, bootmap + bootmap_size, "BOOTMAP");
(gdb) s
reserve_early (start=217088, end=221184, name=name@entry=0xc15d27b4 "BOOTMAP")
at arch/x86/kernel/e820.c:895
reserve low memory region for sleep support
Allocate a page from first 1MB of memory for the wakeup routine for when come back from sleop state.
In acpi_reserve_bootmem, first check size of wakeup code.
wakeup_code_start = 0xc14932df
wakeup_code_end = 0xc1497231
Because slab memory allocator not ready, allocate memory below 1MB, after return from routine alloc_bootmem_core, allocated memory shown as follow:
The allocated memory save to global variable as follow
___alloc_bootmem_nopanic (size=size@entry=16384, align=align@entry=32, goal=goal@entry=0, limit=limit@entry=4294967295) at mm/bootmem.c:582 582 if (region) (gdb) p region $10 = (void *) 0xc0036000
(gdb) printf "acpi_realmode = 0x%x\nacpi_wakeup_address = 0x%x\n", acpi_realmode, acpi_wakeup_address
acpi_realmode = 0xc0036000
acpi_wakeup_address = 0x36000
find smp configure
Symmetric multiprocessing(SMP) involves a symmetric multiprocessor system hardware and software architecture where two or more identical processors are connected to a single, shared main memory, have full access to all I/O devices, and are controlled by a single operating system instance that treats all processors equally, reserving none for special purposes. Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors.
SMP systems are tightly coupled multiprocessor systems with a pool of homogeneous processors running independent of each other. Each processor, executing different programs and working on different sets of data, has the capability of sharing common resources (memory, I/O device, interrupt system and so on) that are connected using a system bus or a crossbar.
find_smp_config involves default_find_smp_config, the platform setup functions in x86_init were assigned with the default functions for standard PC hardware.
Inside default_find_smp_config it involves smp_scan_config to scan a signature in follow memory area
1) Scan the bottom 1K for a signature
2) Scan the top 1K of base RAM
3) Scan the 64K of bios
We finally found the signature in bois memory area, reserve the memory area.
$9 = (struct mpf_intel *) 0xc00f0b20
(gdb) p *mpf
$10 = {signature = "_MP_", physptr = 985904, length = 1 '\001',
specification = 4 '\004', checksum = 86 'V', feature1 = 0 '\000',
feature2 = 0 '\000', feature3 = 0 '\000', feature4 = 0 '\000',
feature5 = 0 '\000'}
If the signature is not found in above memory region, scan first 1K of 4K EBDA.
capture kernel space reservation
On i386, the default location a kernel runs from is 1 MB. The capture kernel is compiled and linked to run from a non default location like 16MB. The first kernel needs to reserve a chunk of memory where the capture kernel and associated data can be pre-loaded. Capture kernel will directly run from this reserved memory location. This space reservation is done with the help of crashkernel=X@Y boot time parameter to first kernel, where X is the the amount of memory to be reserved and Y indicates the location where reserved memory section starts.
In reserve_crashkernel after get total memory, it parse boot time command line to get crash_base and crash_size, then reserve memory base on crash_base and crash_size.
iSCSI Boot Firmware Table (iBFT) reservation
The iSCSI Boot Firmware (iBF) Table (iBFT) is a block of information containing various parameters useful to the iSCSI Boot process. The iBFT is the mechanism by which iBF parameter values are conveyed to the operating system. The iBF builds and fills in the iBFT. The iBFT is available to the operating system to enable a consistent flow of the boot process.
Routine reserve_ibft_region used to find the iSCSI Boot Formate Table. The logical kernel address is set in the ibft_addr global variable. Reserved memory for iSCSI Boot Firmware Table.
In our boot, iSCSI Boot Firmware Table is not found.
Breakpoint 3, reserve_ibft_region () at drivers/firmware/iscsi_ibft_find.c:81
81 if (ibft_addr)
(gdb) p ibft_addr
$1 = (struct ibft_table_header *) 0x0
setup page table
A page table is the data structure used by a virtual memory system in a computer operating system to store the mapping between virtual addresses and physical addresses. Virtual addresses are used by the accessing process, while physical addresses are used by the hardware, or more specifically, by the RAM subsystem.
A single array large enough to hold the page table entries for a single process would be huge. On a typical x86 system, a page table entry requires 32 bits, so 1024 of them (covering 4MB of virtual address space) can be stored in one page. If the virtual address space is 3GB (as it is on many x86 systems), 768 pages would be required to hold all of the page table entries. Allocating that much contiguous memory (for each process) would be impossible, even if that sort of memory overhead were tolerable.
The fact is that most processes only use a small portion of the total virtual address space - but the parts they use are widely scattered over that space. Program text lives down near the bottom, heap memory and dynamic libraries are distributed throughout the middle, and the stack is put up at the very top. So the real page table structure must handle a sparse, widely distributed set of virtual addresses without wasting excessive amounts of memory or requiring large, physically-contiguous arrays.
To that end, modern processors which use page tables use a hierarchical, tree structure. This structure allows the table to be broken up into individual pages, and the subtrees corresponding to unused parts of the address space can be absent. The Linux kernel works with a three-level structure which looks like this:
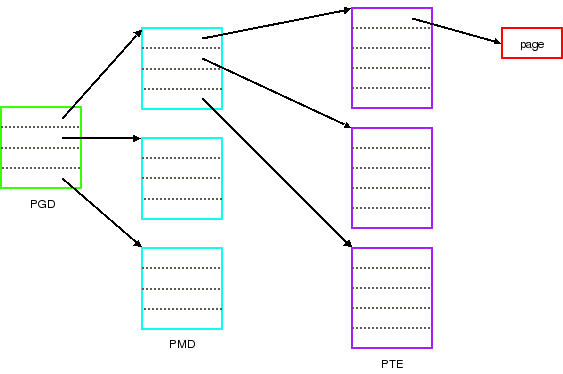
On an x86 system running in the PAE mode (only needed when more than 4GB of memory is installed), all three levels of page tables are present. The page global directory (PGD) contains only four entries, each corresponding to 1GB of virtual address space; the PGD is indexed using the top two bits of the virtual address. Each PGD entry points to a page middle directory (PMD), which holds 512 entries indexed by bits 21-29 of the virtual address. The PMD entry (if it is not empty) points to an actual page table. Using bits 12-20 of the virtual address to index into that page table yields the actual physical address of the page, assuming that page is currently resident in RAM.
in 2.6.11, the page table structure will include a new level, called "PUD," placed immediately below the top-level PGD directory. The new page table structure looks like this:
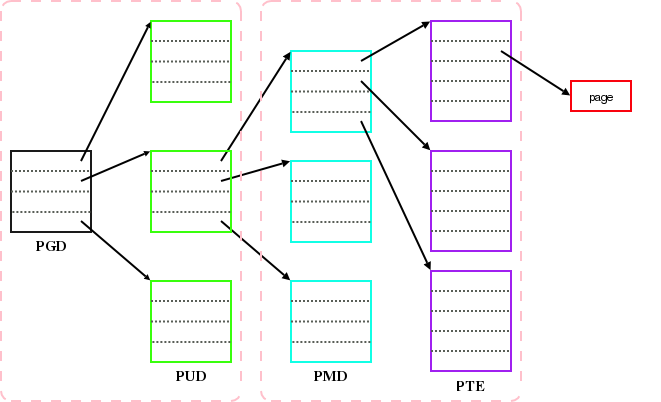
The PGD remains the top-level directory, accessed via the mm_struct structure associated with each process. The PUD only exists on architectures which are using four-level tables; that is only x86-64, as of this writing, but other 64-bit architectures will probably use the fourth level in the future as well. The PMD and PTE function as they did in previous kernels; the PMD is absent if the architecture only supports two-level tables.
Each level in the page table hierarchy is indexed with a subset of the bits in the virtual address of interest. Those bits are shown in the table to the below (for a few architectures). In the classic i386 architecture, only the PGD and PTE levels are actually used; the combined twenty bits allow up to 1 million pages (4GB) to be addressed. The i386 PAE mode adds the PMD level, but does not increase the virtual address space (it does expand the amount of physical memory which may be addressed, however). On the x86-64 architecture, four levels are used with a total of 35 bits for the page frame number. Before the patch was merged, the x86-64 architecture could not effectively use the fourth level and was limited to a 512GB virtual address space. Now x86-64 users can have a virtual address space covering 128TB of memory, which really should last them for a little while.
Architecture Bits used
PGD PUD PMD PTE
i386 22-31 12-21
i386 (PAE mode) 30-31 21-29 12-20
x86-64 39-46 30-38 21-29 12-20
In native_pagetable_setup_start first remove any mappings which extend past the end of physical memory from the boot time page table.
After native_pagetable_setup_start, setup page tables with paging_init.
void __init paging_init(void)
{
pagetable_init();
__flush_tlb_all();
kmap_init();
/*
* NOTE: at this point the bootmem allocator is fully available.
*/
sparse_init();
zone_sizes_init();
}
paging_init call pagetable_init, it further involve permanent_kmaps_init
static void __init pagetable_init(void)
{
pgd_t *pgd_base = swapper_pg_dir;
permanent_kmaps_init(pgd_base);
}
static void __init permanent_kmaps_init(pgd_t *pgd_base)
{
unsigned long vaddr;
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
vaddr = PKMAP_BASE;
page_table_range_init(vaddr, vaddr + PAGE_SIZE*LAST_PKMAP, pgd_base);
pgd = swapper_pg_dir + pgd_index(vaddr);
pud = pud_offset(pgd, vaddr);
pmd = pmd_offset(pud, vaddr);
pte = pte_offset_kernel(pmd, vaddr);
pkmap_page_table = pte;
}
Page table initialized start from address vaddr = 0xffa00000, the first 8MB are already mapped by head.S, here is some information when permanent_kmaps_init calls page_table_range_init.
page_table_range_init (start=start@entry=0xffa00000, end=end@entry=0xffc00000,
pgd_base=<optimized out>) at arch/x86/mm/init_32.c:209
When page table initialization completed, flush TLB with __flush_tlb_all, in __flush_tlb_all if cpu has pge, involve __flush_tlb_global which read, modify and write to CR4.
static inline void __flush_tlb_all(void)
{
if (cpu_has_pge)
__flush_tlb_global();
else
__flush_tlb();
}
and __flush_tlb_global, __flush_tlb_global is a macro, after expanded it involves __native_flush_tlb_global.
static inline void __native_flush_tlb_global(void)
{
unsigned long flags;
unsigned long cr4;
/*
* Read-modify-write to CR4 - protect it from preemption and
* from interrupts. (Use the raw variant because this code can
* be called from deep inside debugging code.)
*/
raw_local_irq_save(flags);
cr4 = native_read_cr4();
/* clear PGE */
native_write_cr4(cr4 & ~X86_CR4_PGE);
/* write old PGE again and flush TLBs */
native_write_cr4(cr4);
raw_local_irq_restore(flags);
}
Cache the first kmap pte with kmap_init.
Initialize memory zone with zone_sizes_init.
Finally involve native_pagetable_setup_done.
Links:
- brk/sbrk
- data segment
- Physical Address Extension
- NX-Bit
- initrd
- kernel parameters
- ACPI in Linux
- ACPI Tables
- The State of ACPI in the Linux Kernel
- Understanding Linux Virtual Memory Manager
- Symmetric multiprocessing(SMP)
- Kdump, A Kexec-based Kernel Crash Dumping Mechanism
- iSCSI Boot Firmware Table (iBFT)
- Page table
- Anatomy of a Program in Memory
- How the Kernel Manages Your Memory
- Page Table Management
- Four-level page tables
- Four-level page tables merged